 Let’s say you run a great team that already has trust, fails and recovers quickly and safely, and sets clear goals, priorities, and limits. (If you don’t, internalize Is it safe? and I can manage.) How do you take a team like that and make it even more productive?
Let’s say you run a great team that already has trust, fails and recovers quickly and safely, and sets clear goals, priorities, and limits. (If you don’t, internalize Is it safe? and I can manage.) How do you take a team like that and make it even more productive?
You could search the internet and my blog postings to find many suggestions for increasing productivity, but how do you know which ones will work for your team? What’s meant by productivity anyway? And how does individual productivity relate to team productivity? Can you feel productive and still not produce much of value?
If team productivity were simple, your team would already be maximally productive and you wouldn’t be reading this sentence. However, team productivity is complex. It’s not a sum of individual productivity, which is already complicated, but instead has a boatload of second-order effects on pacing, blockages, incomplete work, and technical debt. To understand team productivity, you need to go back to basics, learn the elements of productivity, and then apply that knowledge to impact your team’s effectiveness. Fortunately for you, I’ve done that in pretty pictures below.
Do you know how fast you were going?
Look up productivity online, and you’ll see many different measures. At Microsoft, we’ve typically focused on a few common ones: cycle time, throughput (aka delivery rate), bug and work-item counts (aka work in progress or WIP), and response time (aka lead time). Even though they measure different elements of productivity, it turns out these measures are related.
Rather than some cold technical definitions, the easiest way to understand the various productivity measures (and their relationships) is to see them in a cumulative flow diagram.
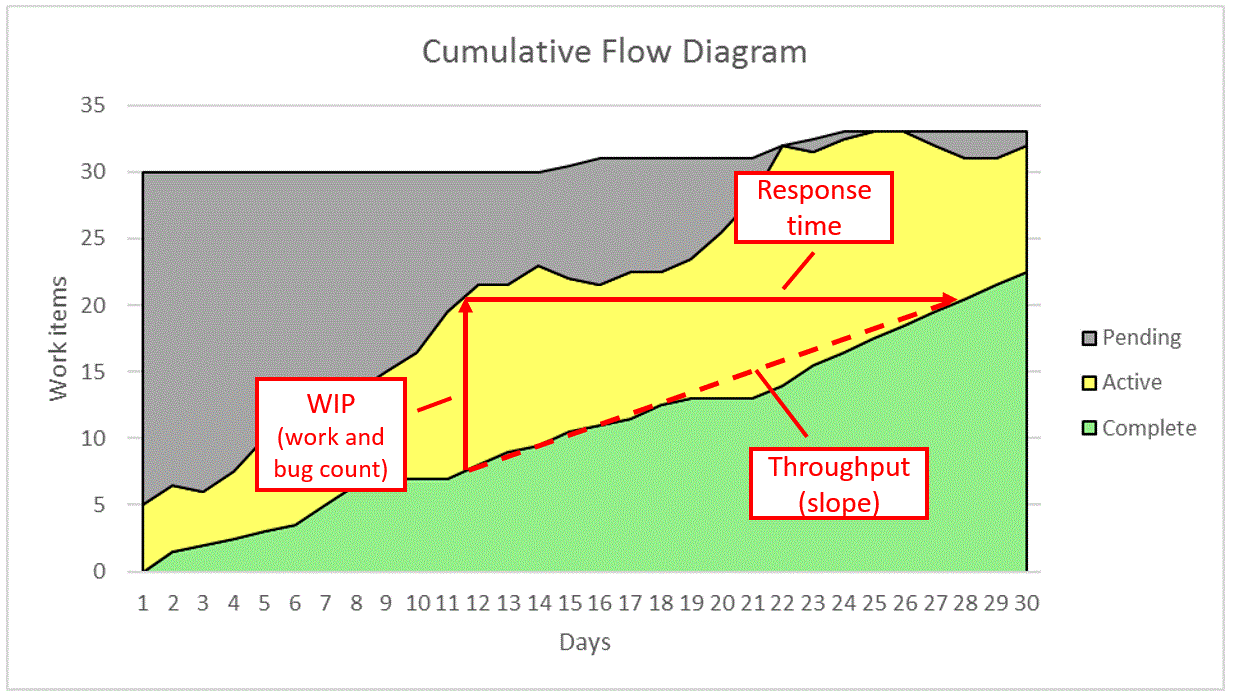
A cumulative flow diagram plots work-item counts (bugs and work) against time, colored by their current state (pending, active, and complete, in this example). On any given day, the work in progress (WIP) is the height of the active portion, the response time is the width of the active portion, and the throughput is the slope of the line connecting them (the slope of completed work over time). Cycle time is the width of the active portion for a specific work item or the reciprocal of throughput, if you want an average over the response time. (In fact, average cycle time can be thought of in many ways, but let’s keep things simple.)
What about me?
Throughput is what many engineers associate with productivity—the faster they get things done, the more productive they feel. WIP is the primary concern of release managers; after all, you can’t ship until all the work is completed and all the bugs are closed. However, response time is how internal and external customers measure the productivity of your team—how quickly can your team respond to a request?
Companies around the world, and internal partner teams around the corner, measure productivity by response time. How quickly can Boeing deliver an ordered airplane or Wendy’s deliver an ordered cheeseburger? How long will your team take to deliver a working feature needed by a team that depends on you? Response time is the productivity measure that matters.
As you can see from the cumulative flow diagram, response time is related to throughput and WIP. Specifically, response time is WIP divided by throughput (a relationship known as Little’s Law). Thus, to improve response time, you need to increase throughput, reduce WIP, or both. (Engineers and release managers are both right.)
Eric Aside
As Bill Hanlon reminded me, another way of measuring response time and health of a codebase is to calculate the average age of bugs (and active work items). The result does not precisely equal response time, but it correlates well and is easy to compute. The higher the average age, the longer your response time and the more technical debt you’ve accumulated.
Finishing more
Here’s a cumulative flow diagram with increased throughput. Notice how the increased slope of throughput has shortened the response time, reflecting work that has gotten done sooner.
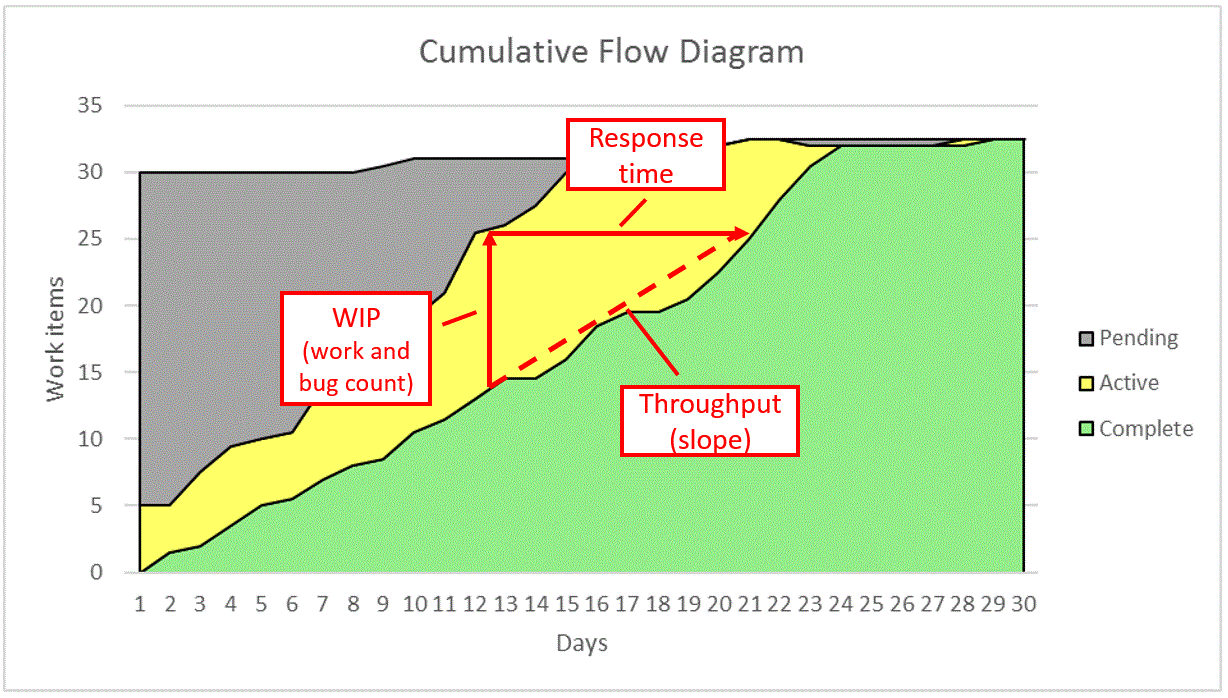
How do you get increased team throughput?
- Ensure fast build, test, sync, and code movement. Your inner loop of development is critical to productivity—make it fast. Once you’ve got code built and tested, ensure it moves quickly to where it’s needed by keeping your branch structure shallow. See Cycle time—the soothsayer of productivity for details.
- Reduce meetings and run them effectively. Nothing kills throughput like overhead and inane, ineffective meetings. Drop meetings, shorten meetings, and run them properly, as described in The day we met.
- Break down work into smaller items. Superficially, this seems superficial. After all, the total work is the same. However, breaking down work gets you started faster and enables you to iterate and adjust faster, which gets you to the goal faster, as I reveal in The value of navigation.
- Track work items, search, and debug quickly and effectively. Make information and bugs easy to find and work-item tracking quick and painless. More about this and other forms of wasted time in Lean: More than good pastrami.
- Co-locate the entire feature team and have daily standups. This speeds communication, which is key to team velocity, as I discuss in Collaboration cache.
Looking back at the cumulative flow diagram, notice that even though the throughput is consistently high, the response time is shorter at the beginning of the period than it is on day 12 (where I drew the arrows). That’s because on day 12, there’s more WIP. Having faster throughput isn’t enough for short and consistent response time—you also need to reduce WIP.
Doing less
Here’s a cumulative flow diagram with reduced WIP. Notice that the response time is shorter than in the previous example, even with clearly lower throughput. The response time is also more consistent, which makes your team more reliable and predictable to your customers and partners.

How do you reduce team WIP?
- Complete features and resolve bugs before doing new features. This is the most fundamental technique for reducing WIP and the basis of feature crews, Kanban, Scrum, and lean software development, as I elaborate in Lean: More than good pastrami.
- Assign work and documentation (specs) just in time. By holding off on assigning work, you avoid people starting work early or having too much.
- Proactively manage dependencies. If you’ve started work that depends on another team, and the dependency comes in late or unstable, you’ve got work in progress that’s stalled. You need to negotiate acceptance criteria and scheduling to avoid such situations, along with contingencies for when they occur anyway, as I describe in You can depend on me.
- Limit bug and technical debt. Carrying around a bunch of unresolved bugs is a recipe for long stabilization periods, slipped schedules, and death marches. Instead, limit your technical debt with bug jail and done definitions, as laid out in The evils of inventory.
- Iterate based on data. The faster you show your work to customers, the sooner you’ll learn what’s wrong with it and the fewer bugs you’ll carry until the end of the project. Code, share, learn, and repeat. (See Data-driven decisions for details.)
- Limit “off-board” projects. Don’t write a feature in secret. Don’t clean up code on a whim. Ask yourself, Is it important? Work in team priority order and avoid surprises—managers hate surprises, and opaque development increases WIP.
Faster throughput gets the work done in less time, but reduced WIP produces even shorter and more reliable response times. Which is better? To customers, the reduced WIP makes the team more responsive and predictable. To operations, faster throughput gets more work done. Naturally, it’s best to do both—increase throughput and reduce WIP.
They’ve gone to plaid
Maybe your team is already pretty agile and practices everything I’ve mentioned. Are you ready to take it to the next level?
Here are more sophisticated techniques for increasing throughput and reducing WIP, but they require significant changes to established team practice.
- Adopt Kanban. This technique achieves the following improvements, as described in Too much of a good thing? Enter Kanban:
- Monitors work on physical boards for instantaneous work-item tracking.
- Makes input and output steps match the pace of your slowest step and applies the theory of constraints (TOC) with drum-buffer-rope to speed your throughput.
- Directly limits your WIP.
- Shorten your critical chain. As TOC tells you, your throughput is constrained by your slowest step. By analyzing your entire engineering flow, you can breakdown steps, parallelize steps, and shorten the critical chain of steps that dictates your throughput. Learn more in chapter 9 of Agile Project Management with Kanban.
- Ensure leads have time for full IC contribution by restricting them to four or fewer reports. Staying small increases productivity and focus. I describe the perfect team size in Span sanity.
- Adopt a DevOps approach. DevOps is painful initially, because it forces your team to fix much of the technical debt that operations hid from you for years. However, that existing debt is real WIP that’s slowing you down. Once you fix it, your response time improves dramatically. Read more in Bogeyman buddy—DevOps.
There is no try
Team productivity may be more complex than individual productivity, but there are straightforward things you can do that have a significant impact. The key is to increase throughput AND reduce work in progress.
Start small. Maybe reduce meetings AND introduce bug jail, or breakdown your work items AND write acceptance tests for your dependencies, or use Kanban to enjoy a number of throughput AND WIP benefits at once. By changing a little at a time, you can experience the benefits without causing too much turmoil and angst.
No matter how you start improving your response time, your customers and partners will notice and appreciate the difference. Being customer obsessed and delivering value soon after it’s requested gets us all closer to the Microsoft we aspire to be.
This is a really awesome article. I will bookmark this and come back to read again and all links as well.
I mostly agree with this, but I think it is missing two important factors that are key to increased productivity.
First, being active is not the same as being productive. You can be active at things that are not really helping you accomplish your goal, and most teams have a ton of process in this area. But they do the process because that’s what they do. Getting faster is a lot about being willing to look at things differently and asking the right questions. For example, you can save a lot of code review time if you adopt pair programming – which gives better results anyway. Or look at the amount of time that is spent with forward and reverse integrations. Or the time spend in bug triage.
Second, productivity is also about doing things that are valuable to the business/customer and not doing things that are not. Most teams don’t have a good idea what is really valuable to the customer, and therefore waste time building features that don’t matter. If your team isn’t working on the most critical business need on an ongoing basis, you aren’t being productive.
First, it is very common for teams to confuse activity with productivity.